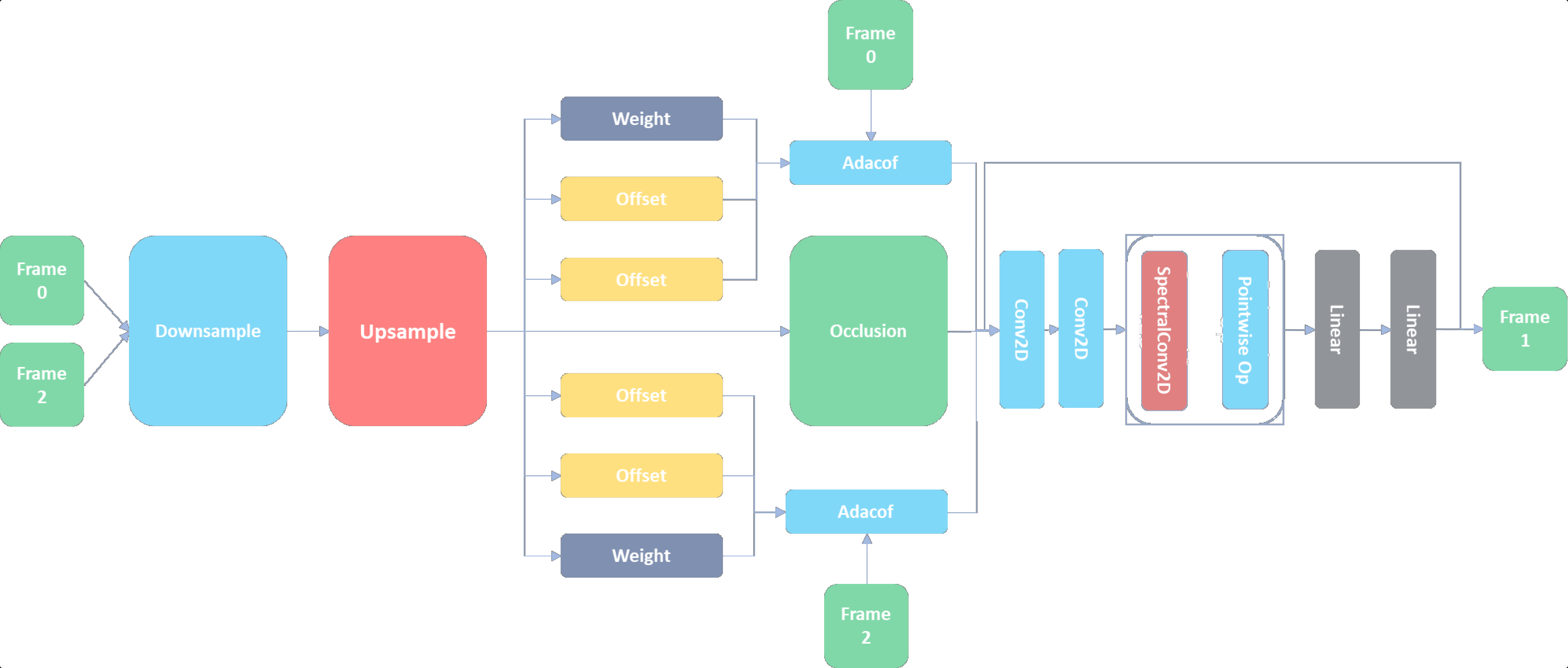
We present, AdaFNIO - Adaptive Fourier Neural Interpolation Operator, a neural operator-based architecture to perform synthetic frame generation. Current deep learning-based methods rely on local convolutions for feature learning and suffer from not being scale-invariant, thus requiring training data to be augmented through random flipping and re-scaling. On the other hand, \textbf{AdaFNIO} leverages the principles of physics to learn the features in the frames, independent of input resolution, through token mixing and global convolution in the Fourier spectral domain by using Fast Fourier Transform (FFT). We show that \textbf{AdaFNIO} can produce visually smooth and accurate results. To evaluate the visual quality of our interpolated frames, we calculate the structural similarity index (SSIM) and Peak Signal to Noise Ratio (PSNR) between the generated frame and the ground truth frame. We provide the quantitative performance of our model on Vimeo-90K dataset, DAVIS, UCF101 and DISFA+ dataset. Lastly, we apply the model to in-the-wild videos such as photosynthesis, brain MRI recordings and red blood cell animations
The model is powerful, resolution invariant, and discretization invari- ant, and achieves state-of-the-art performance on unseen datasets. The model has proven effective in capturing infor- mation in tiny regions of the image (tokens) and generalizing well in larger images.
In the above figure, The leftmost column is a real-time recording of photosynthesis. The middle frame is an animation of plant cells, while the rightmost one is a simulation of red blood cells within the body

The above figure highlights the resolution invari- ance property exhibited by the architecture. The models were trained on 256x256 patches of the Vimeo90K dataset but tested against high-resolution stock footage of the Japanese landscape. In this figure, the top row is the generated out- put and the bottom row is the ground truth. The left row is of 480p resolution, the center one 720p and the right one 1080p
@article{viswanath2022nio,
title={NIO: Lightweight neural operator-based architecture for video frame interpolation},
author={Viswanath, Hrishikesh and Rahman, Md Ashiqur and Bhaskara, Rashmi and Bera, Aniket},
journal={arXiv preprint arXiv:2211.10791},
year={2022}
}