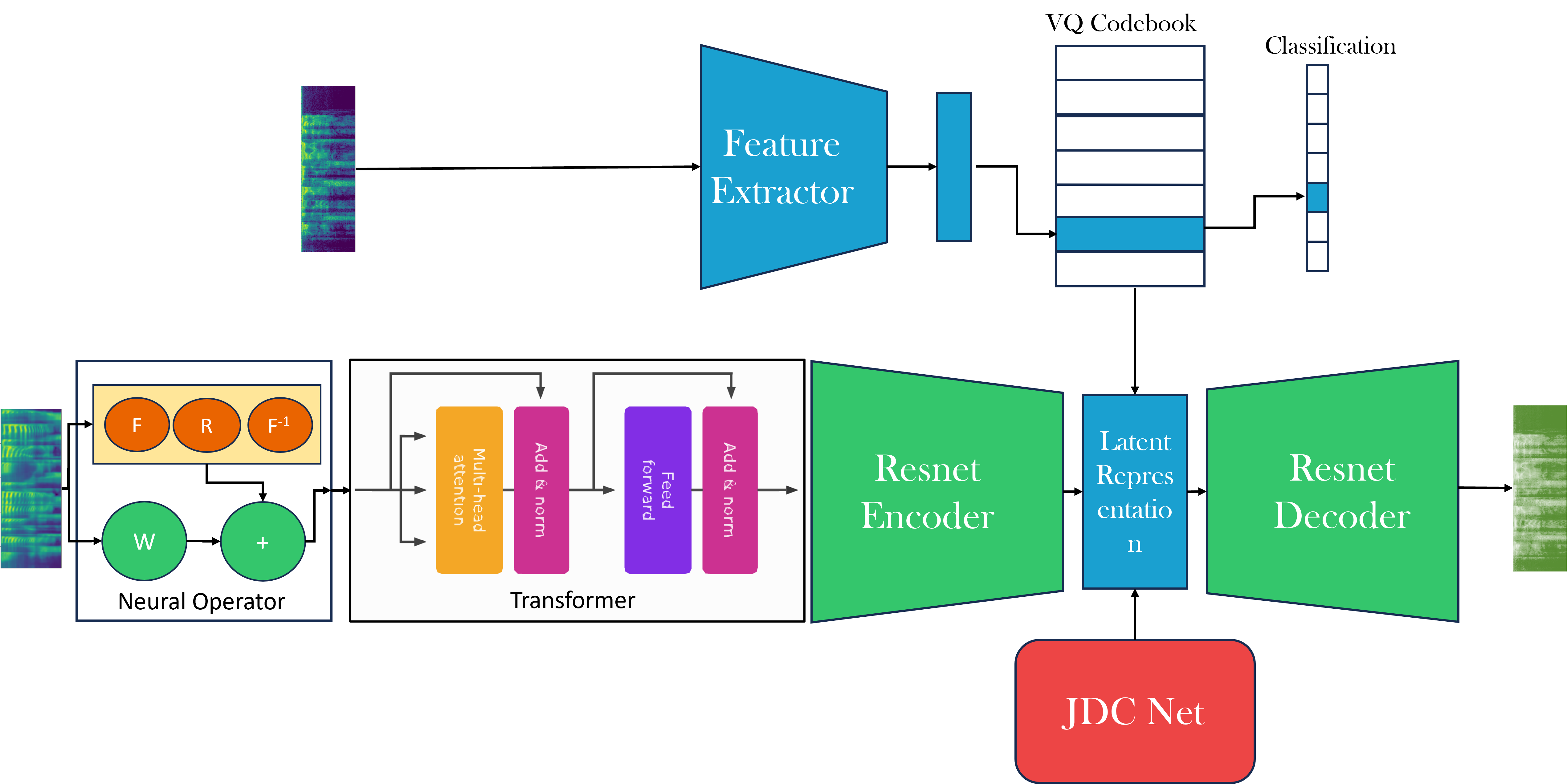
Affect is an emotional characteristic encompassing valence, arousal, and intensity, and is a crucial attribute for enabling authentic conversations. While existing text-to-speech (TTS) and speech-to-speech systems rely on strength embedding vectors and global style tokens to capture emotions, these models represent emotions as a component of style or represent them in discrete categories. We propose AffectEcho, an emotion translation model, that uses a Vector Quantized codebook to model emotions within a quantized space featuring five levels of affect intensity to capture complex nuances and subtle differences in the same emotion. The quantized emotional embeddings are implicitly derived from spoken speech samples, eliminating the need for one-hot vectors or explicit strength embeddings. Experimental results demonstrate the effectiveness of our approach in controlling the emotions of generated speech while preserving identity, style, and emotional cadence unique to each speaker. We showcase the language-independent emotion modeling capability of the quantized emotional embeddings learned from a bilingual (English and Chinese) speech corpus with an emotion transfer task from a reference speech to a target speech. We achieve state-of-art results on both qualitative and quantitative metrics.
Vector quantized embeddings are, in a broad sense, interpretable; however, the individual features of the 64-feature vector representing the quantized emotion cannot be tuned manually to translate the emotion. The use of quantized vectors ensures that out-of-distribution speech samples are still mapped to the nearest known em- beddings, preserving the robustness and generalization ca- pacity of the emotion representation. AffectEcho performs well in cross-language settings and accurately mapps similar emotions together, across languages. AffectEcho has an overall lower MCD score compared to other state of the art models. Furthermore, while the other models generate emotional speech with good accuracy, they fail to incorporate affective features from the human speaker, with whom they are interacting. AffectEcho aims to bridge this gap and showcase stronger human-AI in- teraction capabilities by capturing variations in valence, arousal and dominance.
The following section demonstrates the model's ability to translate emotions in English language, when the reference is in English.
Source |
Reference Audio |
Output |
The following section demonstrates the model's ability to translate emotions in English language, when the reference is in Chinese.
Source |
Reference Audio |
Output |
The following section demonstrates the model's ability to translate emotions in Chinese language, when the reference is in Chinese.
Source |
Reference Audio |
Output |
The following section demonstrates the model's ability to translate emotions in Chinese language, when the reference is in English.
Source |
Reference Audio |
Output |
@article{viswanath2023affectecho,
title={AffectEcho: Speaker Independent and Language-Agnostic Emotion and Affect Transfer for Speech Synthesis},
author={Viswanath, Hrishikesh and Bhattacharya, Aneesh and Jutras-Dub{\'e}, Pascal and Gupta, Prerit and Prashanth, Mridu and Khaitan, Yashvardhan and Bera, Aniket},
journal={arXiv preprint arXiv:2308.08577},
year={2023}
}